






I. Introduction▲
Vous trouverez toutes les sources de cet article sous la forme de projet netbeans : sources.zip.
I-A. Motivations▲
J'ai écrit cet article à la suite de mon projet Algoid lequel inclut un petit langage cousu main. Lors de l'écriture des spécifications de ce langage, j'ai pris conscience d'un certain nombre de choses.
Notamment (lors de la définition des AST) que les objets et les fonctions n'étaient pas si différents que cela. Par ailleurs en JavaScript, les objets sont définis à partir de fonctions en leur adjoignant des méthodes et des attributs. Sorte de fonction composite.
Étant programmeur Java, je sais qu'il n'est pas possible de passer des fonctions en paramètre à d'autres fonctions. Mais des objets si ! Je me suis donc demandé s'il était possible de trouver un moyen de faire tenir une fonction dans un objet afin de résoudre cette incapacité. Des recherches m'ont amené à découvrir le pattern fonction object (plus connu sous le nom de foncteurs) et la thèse de M. Kühne que je vais développer.
En outre, cet article n'a pas la vocation de vous présenter une bibliothèque « clé en main ». Voyez plutôt cela comme une sorte de réflexion à haute voix des possibilités d'un tel pattern. J'aimerai apporter des solutions à des problèmes usuels, mais surtout des pistes de réflexion.
Pour ce qui est des bibliothèques, il en existe de très bien comme Guava par exemple. Java 8 quant à lui apportera toutes ces possibilités lors de sa sortie début 2014.
Vous vous dites sûrement : mais pourquoi écrire un tel article si tous les problèmes seront résolus avec Java 8 ? Eh bien, parce que d'une part c'est la solution de facilité et que réfléchir à ce design pattern nous prépare déjà aux closures ; à en comprendre les fondements et les problématiques. Et d'autre part, parce que tout le monde n'a pas la chance de pouvoir sauter sur le dernier framework en vogue dès sa sortie. Bien des entreprises ont une migration des outils plutôt lente et encore peu d'entre elles ont passé le cap du Java 7 pourtant sorti depuis deux ans.
I-B. Un peu d'histoire▲
(* DJ, mettez-nous la musique d'amicalement vôtre, s'il vous plaît ! … voilà, c'est mieux … *)
Le paradigme fonctionnel est un des plus anciens paradigmes de programmation. En effet il prend sa source dans le langage Lisp58 créé deux années avant Algol60 (impératif/branchements). Ces deux langages sont issus du premier langage formel : Fortran54 (impératif if/goto).
Lisp a pris une voie radicalement différente d'Algol à tel point que ces deux langages ont créé deux courants de pensée bien distincts. Lisp a donné naissance aux langages fonctionnels, dont fait partie la lignée ML. De son côté, Algol (spécifié par John Backus et Peter Naur) a ouvert la voie, d'abord aux langages procéduraux comme le PL/0 (puis Pascal), A, B et C, puis aux langages à objet (dont Simula est l'initiateur). L'objet est donc, historiquement du moins, une extension de l'impératif.
On a longtemps cru que les deux paradigmes étaient incompatibles, voire opposés (comme Lord Sinclair et Danny Wild). Les langages fonctionnels ont été relayés (à tort à mon sens) au rang de langage académique, et les langages impératifs puis objet ont trouvé une place de choix dans l'industrie.
Voici une vue logique des deux grandes familles de langages :
| Impératif | Déclaratif |
| Procédural | Fonctionnel |
| Orienté objet | Logique (programmation par contrainte) |
| Orienté Aspect | |
Le premier langage à réellement tenter une réconciliation entre ces deux mondes est le Smalltalk80, mais il semble aujourd'hui (à tort à mon sens également) être tombé dans l'oubli.
Mais plus récemment, nous avons assisté à un engouement nouveau pour cette réconciliation : Python fut le premier des langages interprétés à rouvrir la voie en 1990 suivi de Ruby en 1995. Quant aux langages compilés (ou pseudocompilés plus précisément), il faudra attendre Groovy, Scala en 2003 et Clojure en 2007.
Constatant leur succès (à juste titre) les autres langages, initialement orientés objet, sont en train de sauter le pas de la réconciliation. D'abord C++ avec les pointeurs de fonctions, C# a introduit les expressions lambda en 2007 dans sa version 2.0 du framework et nous, développeurs Java, attendons avec une impatience non dissimulée, la version 8 de notre langage favori qui en fera de même.
En attendant que la version 8 de Java soit officiellement sortie, je vous propose quelques interfaces qui vont permettre de faire du fonctionnel dans notre langage préféré.
I-C. Le paradigme fonctionnel▲
Son fondement se base sur deux idées principales :
- rejeter le changement et la mutation d'état : une fois créé, un état ne peut plus être modifié ;
- la fonction, quant à elle se comporte comme un état, elle peut être passée en paramètre, retournée, modifiée.
Le paradigme fonctionnel apporte plusieurs avantages :
- comme la possibilité d'effets de bord est réduite, le code est plus facilement maintenable ;
- les possibilités de factorisation sont plus nombreuses qu'avec des procédures (ou méthodes) complètement statiques.
Voici un exemple en AL, le petit langage dont je parlais en introduction. Il est résolument multiparadigme et sa syntaxe est très simple et très proche de Java. Idéal pour illustrer mes propos.
Voici donc un exemple de factorisation possible avec un langage fonctionnel (AlgoidLanguage) :
function myLoop (function f) {
for (int i=0; i<10; i++) {
f(int i);
}
}
function myF(i) {
print ("iteration " + i);
}
myLoop(myF);Qu'on va facilement reconnaître :
iteration 0
iteration 1
iteration 2
iteration 3
iteration 4
iteration 5
iteration 6
iteration 7
iteration 8
iteration 9Une des problématiques majeures de la programmation orientée objet est la séparation des responsabilités et l'extensibilité des bibliothèques. Un comportement n'est pas nécessairement défini lors de la création de la bibliothèque, mais devra l'être a posteriori, lors de son utilisation. C'est le cas par exemple des listes génériques dont l'algorithme de tri sera à la discrétion du programmeur.
En Java, on peut imaginer utiliser une interface :
public class MyList {
public void sort (Sorter sorter) {
sorter.sort(this);
}
}
public interface Sorter {
public int sort (MyList list);
}
public class DefaultSorter implements Sorter {
public int sort(MyList list) {
// le comportement de trie par défaut
}
}
public class MySorter implements Sorter {
public int sort(MyList list) {
// mon comportement de trie
}
}
MyList myList = new MyList().sort(new DefaultSorter());
MyList myList = new MyList().sort(new MySorter());
// n'auront pas le même comportement de trie.On appelle ça de la délégation, de l'injection de dépendance (voir les travaux de Martin Fowler à ce sujet).
Sans aller si loin, on peut voir ici une belle application du design pattern StrategycommandeGoF (ou ) du .
II. Function object▲
II-A. Fonction de premier ordre▲
Ce qu'apporte l'idiome « fonction de premier ordre », c'est de donner la possibilité au programme de choisir le comportement qu'il souhaite pour un traitement. Les comportements deviennent interchangeables au runtime. Par exemple l'utilisateur pourra choisir son ordre de tri depuis l'IHM. En réalité, le fait de considérer un comportement comme paramètre (ce que décrivent les patterns CommandStrategy et du GoF), revient à faire du fonctionnel avec un langage objet.
Ces design patterns présentent des interfaces très simples. Ils ne considèrent pas le passage de paramètre ni le retour de la fonction. Une implémentation dans les framework Java de ces design patterns est l'interface Runnable.
Un design pattern décrit plus précisément une interface capable de coller au plus juste avec les fonctions ; le design pattern Function object (à tort peu connu) dont M.Thomas Kühne fait la description dans sa thèse.
Partant de son travail, je me suis permis (pourvu qu'il ne m'en tienne pas rigueur) d'ajouter deux aspects :
- la faculté d'accepter un nombre variable de paramètres ;
- que les paramètres soient typés grâce aux génériques.
Notre interface doit donc répondre à plusieurs critères :
- représenter une fonction ;
- admettre une valeur de retour typée ;
- admettre un nombre variable de paramètres d'entrée ;
- typer les paramètres indépendamment.
II-B. Guava▲
Thierry Leriche-Dessirier m'a très justement fait remarquer que mes interfaces ressemblaient à celles disponibles dans le framework Guava de Google. Ce n'est pas la seule bibliothèque où j'ai pu rencontrer une implémentation de ce pattern ; les bibliothèques Trove et Colt en font aussi un excellent usage. Malheureusement, ces implémentations ne répondent pas aux deux derniers critères que nous avons fixés. À savoir la possibilité d'admettre un nombre variable (et paramétrable en nombre et en type) d'arguments en entrée. En somme d'avoir une interface qui respecte intégralement la signature de la méthode visée.
II-C. Implémentation simple :▲
Je vais donc vous présenter tout le cheminement qui m'a conduit à l'interface finale. Si vous êtes pressé, vous pouvez vous rendre directement au chapitre implémentation complète.
J'ai donc imaginé une application du pattern fonction objet à Java, essayant de le rendre le plus générique possible : toute méthode, quelle que soit sa signature, devra pouvoir être encapsulé dans un objet réalisant cette interface. Permettant ainsi les fonctions de premier ordre (first class function) :
- fonctions anonymes ;
- enchaînement des appels ;
- arguments fonctionnels ;
- retours fonctionnels.
Le but est donc de créer une interface dont la responsabilité est de représenter une fonction, avec ses paramètres d'entrée et sa valeur de retour :
public interface Function<R, A> {
public R invoke(A... args);
}R est le type de retour de la méthode (Return).
A est le type des paramètres d'entrée (Arguments).
Ce qui permettrait l'écriture de notre liste ordonnée ainsi :
public class MyList {
public void sort (Function<Integer, MyList> sorter) {
sorter.invoke(this);
}
}
public class DefaultSorter implements Function<Integer, MyList> {
public Integer sort( MyList list) {
// le comportement de trie par défaut
}
}
MyList myList = new MyList() ;
myList.sort(new DefaultSorter());
// inline :
List myList = new List() ;
myList.sort(new Function<Integer, List> {
public Integer invoke (List... list) {
// mon comportement
}
});II-D. Polymorphisme des arguments▲
Cette interface est bien, elle implémente très simplement le pattern function object et permet de créer des fonctions avec plusieurs paramètres d'entrée et une valeur de retour.
Malheureusement, ces paramètres se retrouvent obligatoirement du même type.
N'y a-t-il pas un moyen de créer une fonction avec des paramètres de types différents ?
Pour cela, il suffit de créer une classe générique Arguments, qui mettra a disposition des états de natures différentes.
public class Arguments<A1, A2, A3, A4> {
// arguments
private A1 argument1;
private A2 argument2;
private A3 argument3;
private A4 argument4;
// accesseurs
public A1 getArgument1() {
return argument1;
}
public A2 getArgument2() {
return argument2;
}
public A3 getArgument3() {
return argument3;
}
public A4 getArgument4() {
return argument4;
}
// différents constructeurs
public Arguments(A1 argument1) {
this.argument1 = argument1;
}
public Arguments(A1 argument1, A2 argument2) {
this.argument1 = argument1;
this.argument2 = argument2;
}
public Arguments(A1 argument1, A2 argument2, A3 argument3) {
this.argument1 = argument1;
this.argument2 = argument2;
this.argument3 = argument3;
}
public Arguments(A1 argument1, A2 argument2, A3 argument3, A4 argument4) {
this.argument1 = argument1;
this.argument2 = argument2;
this.argument3 = argument3;
this.argument4 = argument4;
}
}L'interface Function serait transformée ainsi :
public interface Function<R, A1, A2, A3, A4> {
R invoke (Arguments<A1, A2, A3, A4> arguments);
}Que l'on pourra utiliser ainsi :
void invokeFunction(Function<Integer, Integer, Void, Void, Void> functionToInvoke) {
functionToInvoke.invoke(new Arguments(5));
}Et l'utilisation de tout ceci :
invokeFunction(new Function<Integer, Integer, Void, Void, Void>() {
@Override
public Integer invoke(Arguments<Integer, Void, Void, Void> arguments) {
return arguments.getArgument1() * 2;
}
});L'avantage est que les arguments de la fonction peuvent être de types hétérogènes.
Le seul problème est que leur nombre n'est pas dynamique. Il faut en définir un certain nombre au départ et annuler le surplus avec un objet "Void". En l'état, nous devons choisir entre une ou l'autre option : soit le type est le même pour tous les arguments, mais leur nombre est variable. Soit on peut configurer les types, mais leur nombre reste fixe et limité.
II-E. Implémentation complète : pluralité des arguments▲
Un moyen de paramétrer le nombre d'arguments souhaité à la fonction consiste à définir une classe pour chaque groupe de paramètres 0, 1, 2, 3, 4, etc.
Si la méthode nécessite 2 arguments, Argument2 sera utilisé, etc.
Ces classes sont définies comme une chaîne d'héritage, 4 hérite de 3 qui hérite à son tour de 2, etc.
Cette architecture présente divers avantages :
- le comportement des getter et des constructeurs ne sera pas dupliqué ;
- en utilisant un générique au niveau de l'interface méthode, on donne la possibilité de configurer la signature (en type et en nombre d'arguments) de la méthode souhaitée :
public class Arguments0<> {
}
public class Arguments1<A1> extends Arguments0 {
private A1 argument1;
public A1 getArgument1() {
return argument1;
}
public Arguments1(A1 argument1) {
this.argument1 = argument1;
}
}
public class Arguments2<A1, A2> extends Arguments1<A1> {
private A2 argument2;
public A2 getArgument2() {
return argument2;
}
public Arguments2(A1 argument1, A2 argument2) {
super(argument1);
this.argument2 = argument2;
}
}
public class Arguments3<A1, A2, A3> extends Arguments2<A1, A2> {
private A3 argument3;
public A3 getArgument3() {
return argument3;
}
public Arguments3(A1 argument1, A2 argument2, A3 argument3) {
super(argument1, argument2);
this.argument3 = argument3;
}
}
public class Arguments4<A1, A2, A3, A4> extends Arguments3<A1, A2, A3> {
private A4 argument4;
public A4 getArgument4() {
return argument4;
}
public Arguments4(A1 argument1, A2 argument2, A3 argument3, A4 argument4) {
super(argument1, argument2, argument3);
this.argument4 = argument4;
}
}Voici la nouvelle interface Function :
public interface Function<R, A extends Arguments0> {
R invoke (A arguments);
}Ce qui est important ici, c'est le paramètre de type A étend Argument0, qui permet la paramétrisation du nombre d'arguments à la fonction.
Notre code d'exemple d'utilisation sera ainsi modifié :
public static void invokeFunction(Function<Integer, Arguments2<Integer, Integer>> functionToInvoke) { // signature précise
System.out.println("Résultat : " + functionToInvoke.invoke(new Arguments2<Integer, Integer>(5, 7)));
}
public static void main(String[] args) {
invokeFunction(new Function<Integer, Arguments2<Integer, Integer>>() {
@Override
public Integer invoke(Arguments2<Integer, Integer> arguments) {
return arguments.getArgument1() * arguments.getArgument2();
}
});
}Le but de tout cela est :
- utiliser une interface générique de délégation comportementale ;
- utiliser les possibilités du langage et de ce fait : être performant ;
- définir une signature précise de la méthode (grâce aux génériques) ;
- et donc : garantir l'intégrité des types, pas de transtypage nécessaire.
Je pense donc que cette petite portion de code trouve sa place dans un toolkit maison pour simplifier l'utilisation du fonctionnel dans nos développements. Surtout lors de créations de bibliothèques ayant trait aux listes et aux délégations comportementales (commandes, callback, arbres, etc.). Car ce qui est rendu plus accessible devient plus souvent utilisé.
II-F. Quelques interfaces▲
De cette première interface, nous pouvons en dériver deux autres.
Dans le cas où la fonction ne renvoie pas de résultat (procédure) :
public interface Procedure<A extends Arguments0> {
void invoke (A arguments);
}Et pour effectuer un test, on parle souvent de prédicat que voici :
public interface Predicate<A extends Arguments0> extends Function<Boolean, A> {}Qui se contente de fixer le type de la valeur de retour en booléen par rapport à l'interface initiale.
III. Implication dans les design patterns▲
Je pense que la partie structurelle des patterns du GoF a été rédigée pour répondre au manque du paradigme fonctionnel dans les langages à objet.
Les design pattern StrategyCommand / en sont son fondement.
On peu voir le pattern function object comme une extension du pattern Strategy, il est donc possible de le substituer dans les patterns du GoF et de réfléchir aux impacts que cela induit.
Rappelons que cette démarche sera d'autant plus vraie lorsque les expressions lambda de Java 8 seront disponibles.
III-A. Délégation comportementale (Strategy)▲
La première idée qui nous vient en tête, c'est la capacité d'un tel outil pour déléguer des comportements. Ce n'est pas pour rien que les foncteurs de c# s'appelaient des Delegates (qui ont eux aussi été remplacés au profit des lambdas).
Revoyons un peu les définitions :
- le design pattern Strategy permet d'encapsuler un algorithme dans un objet afin de rendre son utilisation interchangeable ;
- le pattern function object permet d'encapsuler une fonction dans un objet afin de rendre son utilisation interchangeable.
Il y a comme une similitude !
Je vais maintenant reproduire l'exemple trouvé ici avec nos nouvelles interfaces. Il s'agit de faire voyager un touriste, sans savoir à l'avance la nature du voyage (avion ou voiture).
Voici notre touriste :
public class Tourist {
Procedure<Arguments0> travelMode;
String name;
public Tourist(String name ){
this.name = name;
}
public void setTravelMode(Procedure<Arguments0> travelMode){
this.travelMode = travelMode;
}
public void travel(){
this.travelMode.invoke(null);
}
}Définissons maintenant nos modes de transport :
Procedure<Arguments0> byRoad = new Procedure<Arguments0>() {
@Override
public void invoke(Arguments0 arguments) {
System.out.println("Travelling via road");
}
};
Procedure<Arguments0> byAir = new Procedure<Arguments0>() {
@Override
public void invoke(Arguments0 arguments) {
System.out.println("Travelling via air");
}
};Et reproduisons l'exemple donné :
Tourist t1 = new Tourist("John");
Tourist t2 = new Tourist("Allen");
t1.setTravelMode(byRoad);
t2.setTravelMode(byAir);
t1.travel();
t2.travel();En comparant avec l'exemple original, on s'aperçoit d'une chose : à la différence du pattern Strategy, il n'a pas été nécessaire de créer une superclasse à notre algorithme. Nous réutilisons la superinterface définissant notre foncteur. Et comme cette interface est générique, elle répond à tous nos besoins de délégation. Quelle que soit la signature nécessaire.
Voilà ! Tout l'intérêt est là ! Tout ce qui va suivre maintenant ce sont de différents cas d'utilisation de ce principe. Au travers des patterns et de problématiques usuelles.
III-B. Command▲
III-B-1. Principe▲
Nous avons montré qu'il était possible de passer des fonctions en paramètre, de les stocker dans des variables. Alors, pourquoi pas dans des listes :
private interface CommandFunction extends Function<Void, Arguments0> {
};
private static class Command1 implements CommandFunction {
@Override
public Void invoke(Arguments0 arguments) {
System.out.println("Execution de la commande 1");
return null;
}
}
private static class Command2 implements CommandFunction {
@Override
public Void invoke(Arguments0 arguments) {
System.out.println("Execution de la commande 2");
return null;
}
}
private static class Command3 implements CommandFunction {
@Override
public Void invoke(Arguments0 arguments) {
System.out.println("Execution de la commande 3");
return null;
}
}
// ect.
public static void main(String[] args) {
List<CommandFunction> commandList = new LinkedList<CommandFunction>();
commandList.add(new Command1());
commandList.add(new Command2());
commandList.add(new Command3());
// dans l'ordre
for (CommandFunction command : commandList) {
command.invoke(new Arguments0());
}
System.out.println("\n----\n\n");
// au hazard
for (int i = 0; i<10; i++) {
commandList.get((int)(Math.random() * 3)).invoke(new Arguments0());
}
}III-B-2. Cas du serveur FTP▲
Sur le même principe nous pourrions remplacer la liste par une Map<String, Function…> Ce procédé permettrait de développer le récepteur d'une télécommande : un message est envoyé sur le réseau, à la réception il est transmis à la map qui identifie le message et délivre le bon comportement. C'est le cas d'un serveur FTP par exemple : USER, PWD, PASV, NOOP…
Voici comment utiliser ce pattern pour réaliser une télécommande ; les messages arrivent par la couche réseau. Ils sont découpés en un couple COMMANDE/ARGUMENT. Puis sont envoyés au moteur qui va prendre la décision du comportement à effectuer. C'est cette partie qui nous intéresse.
public class FTPServer {
private Map<String, Procedure<Arguments1<String>>> commands;
public FTPServer() {
commands = new HashMap<String, Procedure<Arguments1<String>>>();
commands.put("USER", new Procedure<Arguments1<String>>() {
@Override
public void invoke(Arguments1<String> arguments) {
System.out.println("User [" + arguments.getArgument1() + "] treatment !");
}
});
commands.put("PWD", new Procedure<Arguments1<String>>() {
@Override
public void invoke(Arguments1<String> arguments) {
System.out.println("Is password is good [" + arguments.getArgument1() + "] ?");
}
});
commands.put("NOOP", new Procedure<Arguments1<String>>() {
@Override
public void invoke(Arguments1<String> arguments) {
System.out.println("Do nothing.");
}
});
/* ect .... */
}La map sert ici à associer un comportement à un message de type commande.
Il est ensuite très simple de trouver la commande et de l'appeler :
public void treatMessage(String commandName, String arg) {
// execute command
commands.get(commandName).invoke(new Arguments1<String>(arg));
}Si on y réfléchit bien, cet emploi du pattern ressemble fortement à un switch case que l'on a fait tenir dans des fonctions au lieu des case/break. Et c'est exactement le cas. Sauf que celui-ci présente des avantages très intéressants :
- Switch/Case ne supporte pas les objets (les Strings et Enums à partir de la version 7). Cette structure est très permissive, la clause de comparaison peut être de n'importe quel type ;
- cette structure est parfaitement extensible. Il n'est pas nécessaire de modifier la structure pour ajouter de nouvelles commandes, l'ajout d'un tuple dans la map suffit ;
- cette structure peut être enrichie après coup. Il est possible de fournir les méthodes nécessaires pour que des commandes puissent être enrichies depuis un autre objet.
III-C. Callback (observer/observable)▲
Observer/observable répond à un besoin : notifier un objet afin qu'il effectue l'action adéquate. Une façon plus simple consiste à enregistrer directement la fonction à appeler au niveau de l'observable. Cela s'appelle le callback.
Le callback, tout comme le pattern du GoF, peut être simple ou composite. En effet, il est possible ; soit d'enregistrer un seul observateur, soit plusieurs.
Voici comment nous pouvons implémenter l'objet Callback tel qu'il est défini en JavaScript et ce, grâce à nos foncteurs :
il suffit d'entretenir une liste de nos fonctions à appeler :
public class Callbacks<A extends Arguments0> {
private List<Procedure<A>> callBacks;
public Callbacks() {
callBacks = new ArrayList<Procedure<A>>();
}
public boolean add(Procedure<A> e) {
return callBacks.add(e);
}
public boolean remove(Procedure<A> o) {
return callBacks.remove(o);
}
public void clear() {
callBacks.clear();
}
/* à suivre */Puis de boucler sur les éléments de cette liste pour tous les notifier lors du fire :
/* suite et fin */
public void fire(A arguments) {
for (Procedure<A> procedure : callBacks) {
procedure.invoke(arguments);
}
}
}Voici maintenant comment l'utiliser :
Callbacks<Arguments2<String, Integer>> callBacks = new Callbacks<Arguments2<String, Integer>>();
// fire
System.out.println("Nothing appends !");
callBacks.fire(new Arguments2<String, Integer>("A first fire", 1));
// register 1
callBacks.add(new Procedure<Arguments2<String, Integer>>() {
@Override
public void invoke(Arguments2<String, Integer> arguments) {
System.out.println("My first callback run with values " + arguments.getArgument1() + " " + arguments.getArgument2());
}
});
// fire
System.out.println("\n1 callback runs");
callBacks.fire(new Arguments2<String, Integer>("A second fire", 2));
// register 2
callBacks.add(new Procedure<Arguments2<String, Integer>>() {
@Override
public void invoke(Arguments2<String, Integer> arguments) {
System.out.println("My second callback run .... " + arguments.getArgument1() + " " + arguments.getArgument2());
}
});
// fire
System.out.println("\n2 callback runs");
callBacks.fire(new Arguments2<String, Integer>("A third fire", 3));Le résultat de tout ceci :
Nothing appends !
1 callback runs
My first callback run with values A second fire 2
2 callback runs
My first callback run with values A third fire 3
My second callback run .... A third fire 3Ça ce passe de commentaires !
III-D. Application aux listes (map-filter-reduce)▲
Comme me l'a très justement fait remarquer Thierry, le paradigme fonctionnel est particulièrement utile aux listes.
Les principes qui suivent sont un portage au langage Java des méthodes map-filter-reduce en langage Python.
Note : nous verrons en annexe comment modifier cette classe pour qu'elle puisse être utilisée sur d'autres types de liste.
Nous allons partir de la classe functionalListe suivante :
public class FunctionalList<T> extends ArrayList<T> { /*….*/ }Et d'un exemple très précieux de Thierry, une liste de chiens dont le POJO :
public class Dog {
public enum Gender {
FEMALE, MALE
}
private String name;
private Gender gender;
private int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Gender getGender() {
return gender;
}
public void setGender(Gender gender) {
this.gender = gender;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
// constructeurs
public Dog(String name, Gender gender, int age) {
this.name = name;
this.gender = gender;
this.age = age;
}
@Override
public String toString() {
return "Dog{" + "name=" + name + ", gender=" + gender + ", age=" + age + '}';
}
}et une liste d'exemples d'individus :
private FunctionalList<Dog> dogs = new FunctionalList<Dog>();
// create list
dogs.add(new Dog("effy", Dog.Gender.MALE, 5));
dogs.add(new Dog("wolf", Dog.Gender.MALE, 7));
dogs.add(new Dog("lili", Dog.Gender.FEMALE, 7));
dogs.add(new Dog("poupette", Dog.Gender.FEMALE, 10)); // appeler son chien comme ça devrait être passible de prison
dogs.add(new Dog("rouquette", Dog.Gender.FEMALE, 11));
dogs.add(new Dog("rouky", Dog.Gender.MALE, 8));
dogs.add(new Dog("athos", Dog.Gender.MALE, 3));III-D-1. Each (iterator)▲
Nous avons vu que l'idiome « fonction de premier ordre » permet de factoriser de façon imbriquée. Il devient alors possible d'entretenir une boucle dont le comportement est délégué à un autre objet. Cela répond à la problématique initiale du pattern iterator qui donne accès aux éléments d'une liste sans donner accès à la liste et à sa structure.
Grâce aux foncteurs, nous allons être capables d'aller plus loin qu'avec un iterator. Nous allons utiliser la délégation pour cacher l'itération même (la boucle) en ne déléguant que le comportement à adopter pour chaque élément de la liste.
Voici comment écrire cet itérateur d'un nouveau genre :
public void each(Procedure<Arguments2<T, Integer>> func) {
for (int i = 0; i < size(); i++) {
func.invoke(new Arguments2<T, Integer>(this.get(i), i));
}
}Que nous exploiterons ainsi :
public Procedure<Arguments2<Dog, Integer>> printItems = new Procedure<Arguments2<Dog, Integer>>() {
@Override
public void invoke(Arguments2<Dog, Integer> arguments) {
String name = arguments.getArgument1().getName();
String gender = arguments.getArgument1().getGender().name();
int number = arguments.getArgument2().intValue();
System.out.println("The dog n°" + number + " called " + name + " is a " + gender);
}
};
dogs.each(printItems);Il faut s'imaginer ici le bloc de code comme s'il était imbriqué dans la boucle impérative for.
Qui nous donne le résultat suivant :
The dog n°0 called effy is a MALE
The dog n°1 called wolf is a MALE
The dog n°2 called lili is a FEMALE
The dog n°3 called poupette is a FEMALE
The dog n°4 called rouquette is a FEMALE
The dog n°5 called rouky is a MALE
The dog n°6 called athos is a MALEVoilà le principe de base des méthodes fonctionnelles de notre nouvelle liste. Tout ce qui suit est un dérivé de cela.
III-D-2. Map▲
Map ressemble à Each, à ceci près que cette dernière crée une nouvelle liste contenant le résultat de l'appel du foncteur.
Elle travaille sur une liste en entrée (this) et une liste de sortie :
public <R> FunctionalList<R> map(Function<R, Arguments2<T, Integer>> func) {
FunctionalList<R> result = new FunctionalList<R>();
for (int i = 0; i < size(); i++) {
result.add(i, func.invoke(new Arguments2<T, Integer>(this.get(i), i)));
}
return result; // cascade
}Remarque : les éléments de la liste de sortie ne sont pas nécessairement du même type. Nous avons eu recours à une méthode générique.
Voici une utilisation, par exemple, créons un tableau contenant tous les noms des chiens et seulement cela :
FunctionalList<String> dogNames = new FunctionalList<String>();
dogNames = dogs.map(new Function<String, Arguments2<Dog, Integer>>() {
@Override
public String invoke(Arguments2<Dog, Integer> arguments) {
return arguments.getArgument1().getName();
}
});
System.out.println("list of dog names : " + dogNames);Ce qui donne comme résultat :
list of dog names : [effy, wolf, lili, poupette, rouquette, rouky, athos]Imaginons que nous voulions modifier ce nom au passage en lui mettant une majuscule à la première lettre :
FunctionalList<String> dogNames = new FunctionalList<String>();
dogNames = dogs.map(new Function<String, Arguments2<Dog, Integer>>() {
@Override
public String invoke(Arguments2<Dog, Integer> arguments) {
String name = arguments.getArgument1().getName();
String result = name.substring(0, 1).toUpperCase();
result += name.substring(1);
return result;
}
});
System.out.println("list of dog names : " + dogNames);Ce qui donne comme résultat :
list of dog names : [Effy, Wolf, Lili, Poupette, Rouquette, Rouky, Athos]III-D-3. Filter▲
Filter permet de filtrer les éléments de la liste selon un critère. Le critère est défini comme une fonction dont l'entrée est l'élément de la liste à filtrer et la sortie si oui ou non l'élément fera partie du résultat.
public FunctionalList<T> filter(Predicate<Arguments2<T, Integer>> func) {
FunctionalList<T> result = new FunctionalList<T>();
for (int i = 0; i < size(); i++) {
if (func.invoke(new Arguments2<T, Integer>(this.get(i), i))) {
result.add(this.get(i));
}
}
return result; // cascade
}Nous voulons une sous-liste des chiens mâles :
FunctionalList<Dog> maleDogs = new FunctionalList<Dog>();
maleDogs = dogs.filter(new Predicate<Arguments2<Dog, Integer>>() {
@Override
public Boolean invoke(Arguments2<Dog, Integer> arguments) {
if (arguments.getArgument1().getGender() == Dog.Gender.MALE) {
return true;
} else {
return false;
}
}
});
maleDogs.each(printItems);Et donnera le résultat suivant :
The dog n°0 called effy is a MALE
The dog n°1 called wolf is a MALE
The dog n°2 called rouky is a MALE
The dog n°3 called athos is a MALEIII-D-4. Reduce▲
Et enfin, reduce, qui applique le foncteur aux éléments de la liste et au résultat précédent de façon à traiter la suite. Le résultat est celui de la combinaison de l'élément avec ce résultat.
Reduce est utile pour calculer des sommes, des moyennes, trouver quel élément est le plus grand, etc.
public T reduce(Function<T, Arguments2<T, T>> func) {
T result = null;
if (size() > 0) {
// initialize first result
result = this.get(0);
for (int i = 1; i < size(); i++) {
result = func.invoke(new Arguments2<T, T>(result, this.get(i)));
}
}
return result;
}Nous voulons maintenant connaître le chien le plus âgé de notre liste :
Dog olderDog = dogs.reduce(new Function<Dog, Arguments2<Dog, Dog>>() {
@Override
public Dog invoke(Arguments2<Dog, Dog> arguments) {
if (arguments.getArgument1().getAge() < arguments.getArgument2().getAge()) {
return arguments.getArgument2();
} else {
return arguments.getArgument1();
}
}
});
System.out.println("Le plus vieux chien de tous est " + olderDog.getName() + " il a " + olderDog.getAge() + " ans.");Chaque élément est comparé au résultat précédent. La décision est prise de qui est le plus âgé. Celui-ci est retourné et servira de résultat à l'itération suivante.
Dans le cas de la première itération, c'est l'élément 0 qui est utilisé.
Ce qui nous donne :
Le plus vieux chien de tous est rouquette il a 11 ans.III-D-5. Chaînage des appels▲
Énoncé
Nous désirons maintenant obtenir la somme des âges des chiens mâles de la liste.
Grâce au paradigme fonctionnel et à notre FunctionalList, nous pouvons procéder ainsi :
- appliquer un filter sur le genre du chien ;
- utiliser map afin d'obtenir une sous-liste des âges de ces chiens ;
- effectuer un reduce sur cette sous-liste de façon à en obtenir le cumul.
Note : ce programme est tout à fait réalisable avec FluentIterable de Guava à la différence toutefois que Guava ne gère pas complètement la signature de la méthode de façon générique.
Utilisons un chaînage de nos méthodes fonctionnelles pour calculer la moyenne des âges des mâles :
int sum = dogs.filter(new Predicate<Arguments2<Dog, Integer>>() {
@Override
public Boolean invoke(Arguments2<Dog, Integer> arguments) {
// filter on male
return arguments.getArgument1().getGender() == Dog.Gender.MALE;
}
}).<Integer>map(new Function<Integer, Arguments2<Dog, Integer>>() {
@Override
public Integer invoke(Arguments2<Dog, Integer> arguments) {
// get ages
return arguments.getArgument1().getAge();
}
}).reduce(new Function<Integer, Arguments2<Integer, Integer>>() {
@Override
public Integer invoke(Arguments2<Integer, Integer> arguments) {
// sum âges
return arguments.getArgument1() + arguments.getArgument2();
}
});
System.out.println("Le cumul de l'âge des mâles est de : " + sum + " ans");Ce qui nous donne :
Le cumul de l'âge des mâles est de : 23 ansIII-D-6. Flux▲
Le problème initialement énoncé concernait la moyenne des âges des chiens mâles de la liste.
En voici une solution à ce problème :
Float average = dogs.filter(new Predicate<Arguments2<Dog, Integer>>() {
@Override
public Boolean invoke(Arguments2<Dog, Integer> arguments) {
// filter on male
return arguments.getArgument1().getGender() == Dog.Gender.MALE;
}
}).<Float>map(new Function<Float, Arguments2<Dog, Integer>>() {
@Override
public Float invoke(Arguments2<Dog, Integer> arguments) {
// get ages
return Integer.valueOf(arguments.getArgument1().getAge()).floatValue();
}
}).reduce(new Function<Float, Arguments2<Float, Float>>() {
private int currentIndex = 1; // begin at the second iteration (see reduce implementation)
@Override
public Float invoke(Arguments2<Float, Float> arguments) {
// recursive serie
float prevResult = arguments.getArgument1();
float currentAge = arguments.getArgument2();
currentIndex++;
// calculate
float prevSum = prevResult * (currentIndex - 1); // step 1
float newSum = prevSum + currentAge; // step 2
float newAverage = newSum / currentIndex; // step 3
return newAverage;
}
});
System.out.println("La moyenne des âges des mâles est de : " + average + " ans"); // 5.75
assertEquals(5.75f, average);On obtient :
La moyenne des âges des mâles est de : 5.75 ansEn Java 8, ce genre de méthodes fonctionnelles seront architecturées comme une lecture de flux. Les limites de la liste ne seront pas connues dans le foncteur. Comme un foncteur est un objet, il est facile de lui ajouter un paramètre. L'astuce ici consiste à entretenir le cumul des chiens dont la moyenne a déjà été calculée.
Ensuite on calcule la moyenne selon la suite récurrente suivante :
- on récupère la somme en annulant la moyenne précédente : moyenne * nombre d'individus du cycle précédent ;
- on ajoute l'âge de l'individu courant ;
- on recalcule la moyenne avec le nombre d'individus du cycle en cours.
Si notre flux devait s'arrêter, nous aurions une moyenne des âges intermédiaire.
III-E. Parcours de Composite Depth-First▲
Qui dit liste dit composite!
Tout le monde connait le composite et sait l'écrire. Une des plus belles utilisations du polymorphisme ! Je ne vais donc pas tout réécrire. Juste la partie qui nous intéresse.
Voici le Component :
public abstract class Component {
/* …. partie composite …. */
private String name;
public Component(String name) {
this.name = name;
}
public String getName() {
return name;
}
public abstract void depthFirstSearch(Procedure<Arguments1<Component>> visitor);
}Ce qui est important ici, c'est la méthode depthFirstSearch. Pourquoi depthFirst ? Eh bien parce que nous allons faire un parcours en profondeur de sorte à itérer sur tous les éléments de notre arbre. C'est l'équivalent de la méthode each, mais pour les arbres.
La Leaf :
public class Leaf extends Component{
/* …. partie composite et constructeur …. */
@Override
public void depthFirstSearch(Procedure<Arguments1<Component>> visitor) {
visitor.invoke(new Arguments1<Component>(this));
}
}Facile !
Le Composite :
public class Composite extends Component {
/* …. partie composite et constructeur …. */
@Override
public void depthFirstSearch(Procedure<Arguments1<Component>> visitor) {
visitor.invoke(new Arguments1<Component>(this));
// loop on children
for (Component component : children) {
component.depthFirstSearch(visitor);
}
}
}Pas très compliqué non plus.
Et un programme d'exemple :
Component tree = new Composite("root");
Component node1 = new Composite("node 1");
node1.addChild(new Composite("leaf 1.1"));
node1.addChild(new Composite("leaf 1.2"));
node1.addChild(new Composite("leaf 1.3"));
node1.addChild(new Composite("leaf 1.4"));
tree.addChild(node1);
Component node2 = new Composite("node 2");
node2.addChild(new Composite("leaf 2.1"));
node2.addChild(new Composite("leaf 2.2"));
tree.addChild(node2);
Component node3 = new Composite("node 3");
node3.addChild(new Composite("leaf 3.1"));
node3.addChild(new Composite("leaf 3.2"));
node3.addChild(new Composite("leaf 3.3"));
node3.addChild(new Composite("leaf 3.4"));
node3.addChild(new Composite("leaf 3.5"));
tree.addChild(node3);
tree.depthFirstSearch(new Procedure<Arguments1<Component>>() {
@Override
public void invoke(Arguments1<Component> arguments) {
System.out.println("This is the component : " + arguments.getArgument1().getName());
}
});Ce qui est long ici, c'est la construction de l'arbre. Le reste est très simple.
Ce qui nous donne :
This is the component : root
This is the component : node 1
This is the component : leaf 1.1
This is the component : leaf 1.2
This is the component : leaf 1.3
This is the component : leaf 1.4
This is the component : node 2
This is the component : leaf 2.1
This is the component : leaf 2.2
This is the component : node 3
This is the component : leaf 3.1
This is the component : leaf 3.2
This is the component : leaf 3.3
This is the component : leaf 3.4
This is the component : leaf 3.5Simple, efficace. Des programmes comme on les aime.
On pourrait penser que cette manipulation pourrait nous épargner un visitor. Non, car le visitor utilise le double dispatch pour corréler le type d'élément visité et la méthode dans le visitor.
J'ai trouvé un moyen d'écrire un visiteur basé sur les foncteurs. Je l'ai mis en pratique avec les AST de mon langage AL. Il a même l'avantage de ne plus figer la structure du composite… Mais l'explication risque d'être longue. Je réserve ça pour un prochain article, peut-être.
IV. IOC▲
Le principe d'un framework tel que tinyIOC, Spring et Java CDI est de permettre une interception des appels des méthodes afin d'exécuter des traitements qui n'étaient pas prévus au départ. Nous allons voir ici comment procéder grâce aux foncteurs.
IV-A. Décorateur de foncteurs▲
Les foncteurs sont des objets. Or en objet il est possible d'ajouter des fonctionnalités à des objets grâce au pattern decoratorGoF du . Donc il est possible d'écrire des décorateurs de foncteurs afin d'ajouter des méthodes et d'encapsuler l'appel de la fonction.
public abstract class FunctionDecorator<R, A extends Arguments0> implements Function<R, A> {
// Based on GoF template method.
public abstract void before(A arguments);
public abstract void after(A arguments, R result);
// And decorator : decorated temlate function object ?
private Function<R, A> decoredFunction;
public Function<R, A> getDecoredFunction() {
return decoredFunction;
}
// Based on GoF decorator : function decorator ?
public FunctionDecorator(Function<R, A> decoredFunction) {
this.decoredFunction = decoredFunction;
}
@Override
public R invoke(A arguments) {
R result = null;
// call the before template method
before(arguments);
// call decored funcction
result = decoredFunction.invoke(arguments);
// call the after template method
after(arguments, result);
return result;
}
}Voici une joyeuse fusion de différents patterns : notre function object couplée aux patterns decoratortemplate methodGoF et du . Qui a dit que j'aimais les patterns ?
IV-B. Conteneur IOC▲
Définissions maintenant une classe et remplaçons ses méthodes par des attributs publics dont le type n'est autre que Function. Vous me suivez ? Ce ne sont donc plus des fonctions classiques, mais des foncteurs.
public class Person {
private String name;
private Integer age;
// name getter
public Function<String, Arguments0> getName = new Function<String, Arguments0>() {
@Override
public String invoke(Arguments0 arguments) {
return Person.this.name;
}
};
// age getter
public Function<Integer, Arguments0> getAge = new Function<Integer, Arguments0>() {
@Override
public Integer invoke(Arguments0 arguments) {
return Person.this.age;
}
};
// name setter
public Function<Void, Arguments1<String>> setName = new Function<Void, Arguments1<String>>() {
@Override
public Void invoke(Arguments1<String> arguments) {
Person.this.name = arguments.getArgument1();
return null;
}
};
// age setter
public Function<Void, Arguments1<Integer>> setAge = new Function<Void, Arguments1<Integer>>() {
@Override
public Void invoke(Arguments1<Integer> arguments) {
Person.this.age = arguments.getArgument1();
return null;
}
};
}L'exemple porte sur des accesseurs, mais il est possible d'imaginer toutes sortes de méthodes.
Nous voulons maintenant qu'à chaque appel d'un setter une ligne de log soit ajoutée au fichier de journalisation avant et après l'appel.
Définissons notre décorateur de setter :
public static class SetterLogger extends FunctionDecorator<Void, Arguments1<String>> {
private String functionName;
@Override
public void before(Arguments1<String> arguments) {
System.out.println("Argument [" + functionName + "] will be changed !");
}
@Override
public void after(Arguments1<String> arguments, Void result) {
System.out.println("Argument [" + functionName + "] was changed by " + arguments.getArgument1());
}
public SetterLogger(String functionName, Function<Void, Arguments1<String>> decoredFunction) {
super(decoredFunction);
this.functionName = functionName;
}
}Et voici comment l'utiliser :
// jusqu'ici tout va bien (comme l'écologie)
Person person = new Person();
// on appelle une première fois
System.out.println("Shouldn't log ....");
person.setName.invoke(new Arguments1<String>("John Doe"));
// c'est là que ça commence, on décore notre méthode
person.setName = new SetterLogger("setName", person.setName);
// et on appelle de nouveau
System.out.println("\nShould log ....");
person.setName.invoke(new Arguments1<String>("John Doe"));Voici ce que l'on obtient :
Shouldn't log ....
Should log ....
Argument [setName] will be changed !
Argument [setName] was changed by John DoeTrès bien. Maintenant admettons que nous ayons besoin de revenir en arrière. Retrouver notre méthode originelle.
person.setName = ((FunctionDecorator<Void, Arguments1<String>>) person.setName).getDecoredFunction();Bon c'est au prix d'un cast et peut-être d'une instance of si on n'est pas sûr. Mais avouez que ça peut être pratique.
Allons un peu plus loin. On sait par définition qu'un décorateur peut en décorer d'autres et ainsi de suite. Il est donc possible de décorer plusieurs fois une fonction avec ce principe : admettons maintenant que nous voulions à la fois journaliser l'appel et pérenniser la valeur.
public static class SetterPersistency extends FunctionDecorator<Void, Arguments1<String>> {
@Override
public void before(Arguments1<String> arguments) {
// do nothing
}
@Override
public void after(Arguments1<String> arguments, Void result) {
System.out.println("implement here the value persistency of " + arguments.getArgument1());
}
public SetterPersistency(Function<Void, Arguments1<String>> decoredFunction) {
super(decoredFunction);
}
}Que l'on utilise ainsi :
person.setName = new SetterLogger("setName", new SetterPersistency(person.setName));Ce qui va nous donner lors de l'appel :
Should log and persist ....
Argument [setName] will be changed !
implement here the value persistency of John Doe
Argument [setName] was changed by John DoeVoici encore un bel exemple de la puissance que confère le design pattern function object.
IV-C. Aspect▲
Cet exemple d'utilisation laisserait presque entrevoir le paradigme Aspect.
Malheureusement en l'état, il ne serait pas complet. Nous n'avons pas ici la possibilité de modifier la définition même de l'objet ; il n'est pas possible d'ajouter ou de supprimer des attributs ou des méthodes à notre objet Person.
Pour aller plus loin, je pense qu'il faudrait regarder du côté de framework d'instrumentation (qui fonctionnent par injection de bytecode) tel que Javassist. L'équipe de Javassist est, par ailleurs, en train de développer une application basée sur cette idée : GluonJ.
V. Conclusion▲
Nous pourrions nous amuser un moment à tourner ces patterns, ces principes fondamentaux dans tous les sens. Mais les bonnes choses ont une fin. La liste de ce que l'on peut imaginer n'est pas exhaustive.
Le principe reste toujours le même, chaque fois qu'il y a délégation de comportement afin de séparer des responsabilités, il devient possible d'utiliser le pattern fonction objet.
Il faut voir une façon de penser l'architecture d'un programme d'une nouvelle manière. Ne plus seulement se focaliser sur la mutation des états, mais également considérer la manipulation des comportements (décoration, passage en paramètre, retour, imbrication). Cette réflexion est vraie pour tous les langages fonctionnels, ou comme nous l'avons vu, tous les langages capables d'implémenter les foncteurs.
Mais, comme tout outil puissant de programmation, rappelons qu'il faut l'utiliser à bon escient et ne pas le conjuguer à tort et à travers.
VI. Remerciement▲
Je tiens à remercier toute ma petite famille qui ferme les yeux sur ma geek-attitude et me pardonne mon manque de présence… Du moins parfois.
Merci également à toute l'équipe du forum developpez.com pour leurs lectures patientes, leurs corrections (plus que patientes), leurs encouragements très appréciés et tous les échanges sans lesquels cet article n'aurait sans doute jamais vu le jour. Tout particulièrement Thierry Leriche-Dessirier, Mickaël BARON alias keulkeul, Nemek pour leurs relectures technique avisées et ClaudeLELOUP pour sa prompte correction orthographique.
Vos retours nous aident à améliorer nos publications. N
'hésitez donc pas à commenter cet article sur le forum :
7 commentaires ![]()
VII. À propos de l'auteur▲
Pour ma part, je suis Yann Caron, j'ai 33 ans, Ingénieur en développement logiciel chez Skyguide à Genève. Je suis en train de finir mes études à distance au CNAM en architecture logicielle.
Retrouvez-moi sur Orange head by CyaNn. Ou à mon adresse mail : CyaNn74 (at) gmail (dot) com.
Je suis à l'origine du logiciel Algoid et de son langage AL que vous pouvez retrouver sur le play store ou sur son site officiel. Pour résumer : cette app a l'ambition de simplifier l'apprentissage de la programmation aux enfants à partir de dix ans. Une sorte de « logo like », mais dans un langage dont la syntaxe est proche du C et la sémantique du Python.
Je me suis d'ailleurs inspiré des principes de mon langage pour vous écrire ces quelques (quelques ?) mots.
VIII. Annexes▲
VIII-A. Références▲
La thèse de M.Thomas Kühne dont cet article est inspiré :
Et la version papier :
http://www.amazon.de/Functional-Pattern-System-Object-Oriented-Design/dp/3860647709
Les travaux de Martin Fowler à propos de l'inversion de responsabilité : http://martinfowler.com/articles/injection.html
La description du map-filter-reduce en langage Python : http://www.python-course.eu/lambda.php
VIII-B. Encore plus loin ?▲
Voici les différentes classes obtenues lors des discussions très enrichissantes avec Thierry de Developpez.com.
VIII-B-1. List Decorator▲
L'exemple que nous avons donné est basé sur l'héritage d'ArrayList. Il ne s'applique donc qu'à un seul type de liste. Pour le rendre indépendant, il faut faire tenir les méthodes fonctionnelles dans un décorateur :
public class FunctionalListDecorator<E> extends AbstractList<E> {
private List<E> decored;
public FunctionalListDecorator(List<E> decored) {
this.decored = decored;
Collections.synchronizedList(this);
}
// Répondre à l'interface
@Override
public E get(int index) {
return decored.get(index);
}
@Override
public int size() {
return decored.size();
}
@Override
public boolean add(E e) {
return decored.add(e);
}
@Override
public E set(int index, E element) {
return decored.set(index, element);
}
@Override
public E remove(int index) {
return decored.remove(index);
}
// ajouter nos méthodes fonctionnelles
@Override
public Iterator<E> iterator() {
throw new UnsupportedOperationException("Not supported ! Use functional capabilities.");
}
@Override
public ListIterator<E> listIterator() {
throw new UnsupportedOperationException("Not supported ! Use functional capabilities.");
}
@Override
public ListIterator<E> listIterator(int index) {
throw new UnsupportedOperationException("Not supported ! Use functional capabilities.");
}
// la liste est responsable de son itération, mais délègue quoi faire pour chaque élément.
public void each(Procedure<Arguments2<E, Integer>> func) {
for (int i = 0; i < size(); i++) {
func.invoke(new Arguments2<E, Integer>(this.get(i), i));
}
}
// si nous exploitons le retour de cette fonction, nous avons un équivalent de la fonction map de Python
// renvoie une copie de la liste passée par le filtre de la fonction
public <R> FunctionalList<R> map(Function<R, Arguments2<E, Integer>> func) {
FunctionalList<R> result = new FunctionalList<R>();
for (int i = 0; i < size(); i++) {
result.add(i, func.invoke(new Arguments2<E, Integer>(this.get(i), i)));
}
return result; // cascade
}
// renvoie une sous-liste selon un critère
public FunctionalList<E> filter(Predicate<Arguments2<E, Integer>> func) {
FunctionalList<E> result = new FunctionalList<E>();
for (int i = 0; i < size(); i++) {
if (func.invoke(new Arguments2<E, Integer>(this.get(i), i))) {
result.add(this.get(i));
}
}
return result; // cascade
}
// renvoie le résultat de la combinaison des éléments
public E reduce(Function<E, Arguments2<E, E>> func) {
E result = null;
if (size() > 0) {
// initialize first result
result = this.get(0);
for (int i = 1; i < size(); i++) {
result = func.invoke(new Arguments2<E, E>(result, this.get(i)));
}
}
return result;
}
}VIII-B-2. Parser de CSV (imbrication de foncteurs)▲
Voici un exemple que j'ai tiré des exemples de mon langage AL. Il avait pour rôle de démontrer les capacités fonctionnelles du langage.
Tout d'abord, créons une fonction, qui à partir d'une chaîne de caractères, nous renvoie une FunctionList<String> résultat d'un split (découpé selon un séparateur) :
public FunctionalListDecorator<String> split (String string, String separator) {
String[] strings = string.split(separator);
FunctionalListDecorator<String> result = new FunctionalListDecorator<String>(new ArrayList<String>(Arrays.asList(strings)));
return result;
}Découpons notre csv :
public void testCSVParsing() throws Exception {
String csv = "" +
"element 1.1, element 1.2, element 1.3, element 1.4\n" +
"element 2.1, element 2.2\n" +
"element 3.1, element 3.2, element 3.3\n" +
"element 4.1, element 4.2, element 4.3, element 4.4, element 4.5\n" +
"";
final List<String> flatList = new ArrayList<String>();
split(csv, "\n").<String>map(new Function<String, Arguments2<String, Integer>>() {
@Override
public String invoke(Arguments2<String, Integer> arguments) {
// the line
System.out.println("Line : " + arguments.getArgument1());
split(arguments.getArgument1(), ", ").<String>map(new Function<String, Arguments2<String, Integer>>() {
@Override
public String invoke(Arguments2<String, Integer> arguments) {
// the element
System.out.println("Element :" + arguments.getArgument1());
flatList.add(arguments.getArgument1());
return arguments.getArgument1();
}
});
return arguments.getArgument1();
}
});
System.out.println("Flat result : " + flatList);
}Ça tient en quelques lignes !
Et voici notre résultat :
Flat result : [element 1.1, element 1.2, element 1.3, element 1.4, element 2.1, element 2.2, element 3.1, element 3.2, element 3.3, element 4.1, element 4.2, element 4.3, element 4.4, element 4.5]Et c'est efficace. Bien sûr il n'y a pas de contrôle des erreurs. Mais c'est une belle illustration de la puissance et de l'élégance du fonctionnel.
VIII-B-3. Architecture multicœur▲
L'optimisation des algorithmes sur les machines multicœurs requiert d'architecturer les programmes avec de multiples threads. Thierry m'a indiqué que les méthodes fonctionnelles de Java 8 seraient articulées sur ce principe.
Voici une proposition de la classe FunctionalList qui tire parti de cette optimisation :
Le principe est assez simple ; utiliser des BlockingQueues du package concurency pour synchroniser les écritures/lectures d'un thread à l'autre.
Voici la définition de la classe :
public class ConcurentFunctionalList<E> extends LinkedBlockingQueue<E> { /* … */ }Le thread qui va exécuter notre map :
private static class MapThread<R, E> extends Thread {
protected ConcurentFunctionalList<E> input;
protected ConcurentFunctionalList<R> output;
protected Function<R, Arguments1<E>> func;
public MapThread(ConcurentFunctionalList<E> input, ConcurentFunctionalList<R> output, Function<R, Arguments1<E>> func) {
this.input = input;
this.output = output;
this.func = func;
}
private boolean isLoopFinised() {
return !input.continueIfEmpty && input.isEmpty();
}
public synchronized void run() {
try {
while (!isLoopFinised()) {
E element = input.take();
output.add(func.invoke(new Arguments1<E>(element)));
}
output.continueIfEmpty = false;
System.out.println("MAP TERMINATED !!!!");
} catch (InterruptedException ex) {
Logger.getLogger(ConcurentFunctionalList.class.getName()).log(Level.SEVERE, null, ex);
}
}
}Le principe est le suivant : le thread gère deux files : une en entrée et une en sortie. Il appelle le foncteur sur l'élément de l'entrée en cours et ajoute le résultat à la queue de sortie.
Comme les queues sont bloquantes, tant qu'un élément n'est pas dans la file, le thread est bloqué.
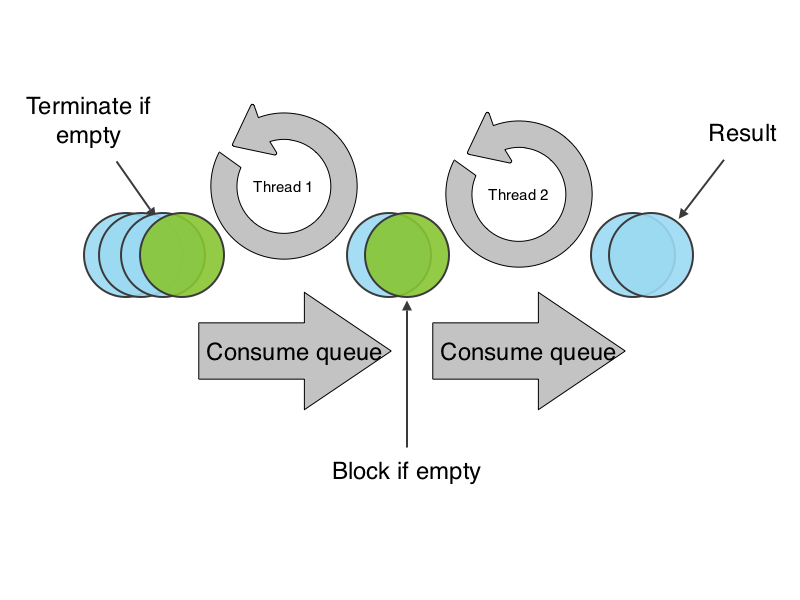
ContinueIfEmpty, indique si le thread est à l'origine de la chaîne ou si c'est un maillon. Dans le premier cas, il devra sortir une fois la file vide, dans le second il devrait attendre. Une chaîne de responsabilités gère ensuite la propagation de cette information dans la chaîne.
Voici comment a été modifiée la méthode fonctionnelle :
public <R> ConcurentFunctionalList<R> map(final Function<R, Arguments1<E>> func) {
ConcurentFunctionalList<R> result = new ConcurentFunctionalList<R>(true);
new MapThread<R, E>(this, result, func).start();
return result;
}Ici rien ne bloque le processus. La file output est créée, le thread initié et démarré, la file est retournée. On peut ainsi chaîner les maps.
ConcurentFunctionalList<Dog> dogs = new ConcurentFunctionalList<Dog>();
dogs.add(new Dog("effy", Dog.Gender.MALE, 5));
dogs.add(new Dog("wolf", Dog.Gender.MALE, 7));
dogs.add(new Dog("lili", Dog.Gender.FEMALE, 7));
dogs.add(new Dog("poupette", Dog.Gender.FEMALE, 10)); // appeler son chien comme ça devrait être passible de prison
dogs.add(new Dog("rouquette", Dog.Gender.FEMALE, 11));
dogs.add(new Dog("rouky", Dog.Gender.MALE, 8));
dogs.add(new Dog("athos", Dog.Gender.MALE, 3));
dogs.<Dog>map(new Function<Dog, Arguments1<Dog>>() {
@Override
public synchronized Dog invoke(Arguments1<Dog> arguments) {
System.out.println("Look element " + arguments.getArgument1().toString());
try {
this.wait(10L);
} catch (InterruptedException ex) {
Logger.getLogger(ConcurentFunctionalListTest.class.getName()).log(Level.SEVERE, null, ex);
}
return arguments.getArgument1();
}
}).<Dog>map(new Function<Dog, Arguments1<Dog>>() {
@Override
public synchronized Dog invoke(Arguments1<Dog> arguments) {
System.out.println("Asychronous second thread " + arguments.getArgument1().toString());
return arguments.getArgument1();
}
});
this.wait(1000L);Remarquons l'utilisation d'un wait à la fin de programme qui permet de le voir s'exécuter. Effectivement le processus n'est pas bloquant. Il serait possible de gérer cela avec des callback. Mais cet exemple est à mon sens suffisamment complexe comme cela. Et puis il faut savoir entretenir un peu de mystère…
Voici le résultat obtenu :
Look element Dog{name=effy, gender=MALE, age=5}
Look element Dog{name=wolf, gender=MALE, age=7}
Asychronous second thread Dog{name=effy, gender=MALE, age=5}
Look element Dog{name=lili, gender=FEMALE, age=7}
Asychronous second thread Dog{name=wolf, gender=MALE, age=7}
Look element Dog{name=poupette, gender=FEMALE, age=10}
Asychronous second thread Dog{name=lili, gender=FEMALE, age=7}
Look element Dog{name=rouquette, gender=FEMALE, age=11}
Asychronous second thread Dog{name=poupette, gender=FEMALE, age=10}
Look element Dog{name=rouky, gender=MALE, age=8}
Asychronous second thread Dog{name=rouquette, gender=FEMALE, age=11}
Look element Dog{name=athos, gender=MALE, age=3}
Asychronous second thread Dog{name=rouky, gender=MALE, age=8}
MAP TERMINATED !!!!
Asychronous second thread Dog{name=athos, gender=MALE, age=3}
MAP TERMINATED !!!!C'est beau à voir !